2024-编译原理-IR篇
1. IR基础知识
“The effectiveness of a compiler depends heavily on the design of its intermediate representation.”
— Keith D. Cooper, Linda Torczon, "Engineering a Compiler", 2nd Edition, 2011.
编译系统的效果在很大程度上取决于 IR(Intermediate Representation,中间表示)的设计。LLVM的成功很大程度上归功于其精良的LLVM IR设计。
一个IR相当于编译架构中的一个抽象层次,一个好的IR为其所在层次上的代码分析、转换、优化提供了便利。
IR解耦了编译器前后端,为多前端、多后端的需求提供了统一的中间表示,下图说明了编译器架构的演化:
1.1 IR的分类
1.1.1 根据抽象层次
- HIR (High-level Intermediate Representation)
- 接近源语言,通常保留了源语言大量抽象层次较高的语法结构
- 例如:AST(抽象语法树),一些高层次的优化如常量折叠、函数内联可以直接在AST上完成
- MIR(Middle-level Intermediate Representation)
- 和源语言和目标语言都无关的IR
- 例如:3AC(3-Address Code,三地址码)
- 大量的机器无关优化在这个层次上实现
- LIR(Low-level Intermediate Representation)
- 通常与目标机器指令一一对应,体现目标平台的底层特征
- 例如:Java JIT编译器的LIR
- 通常可用于做机器相关优化
1.1.2 根据数据结构
树结构
- 如AST
有向无环图(DAG)
DAG在树结构的基础上,消除了冗余的子树
子树的复用使得翻译得到的代码有更少的访存开销
例:基于DAG翻译语句
a = b * (-c) + b * (-c)
线性IR
- 如3AC
1.1.3 根据变量是否允许多次赋值
- 非静态单赋值形式
- 不会引入过多的变量和
指令 - 翻译到机器码时不需要额外的 out of SSA 操作消除
指令 - 主流编译器几乎都采用SSA IR
- 不会引入过多的变量和
- 静态单赋值(SSA)形式:
- 特点:
- 每个变量都只能被赋值一次
- 使用
合并来自多条路径的定义
- 优势:
- 变量的定义使用关系(def-use pairs)非常清晰,方便分析和优化。
- 控制流信息被隐式地包含到独一无二的变量名里面,使得很多优化任务在SSA IR上表现更好。
- 特点:
1.2 IR的评价标准
- 简洁性(Simplicity)
- 可分析性(Analysability)
- 可优化性(Optimisability)
- 目标独立性(Target Independence):尽可能独立于具体的架构或平台,以便支持多后端。
- 可扩展性(Extensibility):方便支持新的源语言特性、新的硬件结构、新的优化策略。LLVM IR强调模块化和可扩展性。
- 良好的抽象层次(Right Level of Abstraction)
2. 三地址码
- 三地址码(3-Address Code,3AC / TAC):每条指令的右侧最多只有一个操作符 / 每条指令最多只能有3个地址
- 地址(Address):可以是常量(如:3)、变量名(如:x)、编译器生成的临时变量(如:t1)
2.1 为什么使用3AC
- 提供一种规范的、标准的代码表示方式
- 易于分析和优化
2.2 一些通用的3AC形式
| 三地址码 | 说明 |
|---|---|
x = y bop z |
x, y, z: 地址;
bop: 二元操作符 |
x = uop y |
uop: 一元操作符 |
x = y |
|
goto L |
L: 标签, 代码程序中一个位置 |
if x goto L |
|
if x rop y goto L |
rop: 关系操作符 (>, <,
=, ...) |
2.3 三地址码示例
源代码
1
2
3do
i = i + 1;
while (a[i + 2] < v);3AC
1
2
3
4
5
6L:
t1 = i + 1
i = t1
t2 = i + 2
t3 = a[t2]
if t3 < v goto L
2.4 三地址码的表示方法
2.4.1 四元式
格式
1
op arg1 arg2 result
例子
2.4.2 三元式
格式
1
op arg1 arg2
与四元式相比,不引入临时变量存放运算结果,而是用指令的位置来表示指令的运算结果
例子
2.4.3 间接三元式
包括:一个直接三元式列表,一个指向每一个直接三元式的指针列表 instruction。
访问指令时,实际上访问的是指针列表 instruction,这样做的好处是方便优化器重新排列 instruction 列表的元素顺序,却并不需要修改任何一个三元式本身。
例子
3. SSA
- SSA(Static Single Assignment,静态单赋值)
- 为每一次变量定义引入一个新的变量名(fresh name)
- 通常使用版本号区分
- 变量随控制流传播并且使用
指令合并 - 每个变量有且仅有一处定义
- 为每一次变量定义引入一个新的变量名(fresh name)
- 变量的定义使用关系(def-use pairs)非常清晰
- 被几乎所有主流编译器所采用
3.1 SSA与3AC的对比
3AC
1
2
3
4
5p = a + b
q = p - c
p = q * d
p = e - p
q = p + qSSA
1
2
3
4
5p1 = a + b
q1 = p1 - c
p2 = q1 * d
p3 = e - p2
q2 = p3 + q1
3.2 控制流合并处理方案
3.2.1 SSA
使用
指令合并来自不同路径的变量定义 例如:
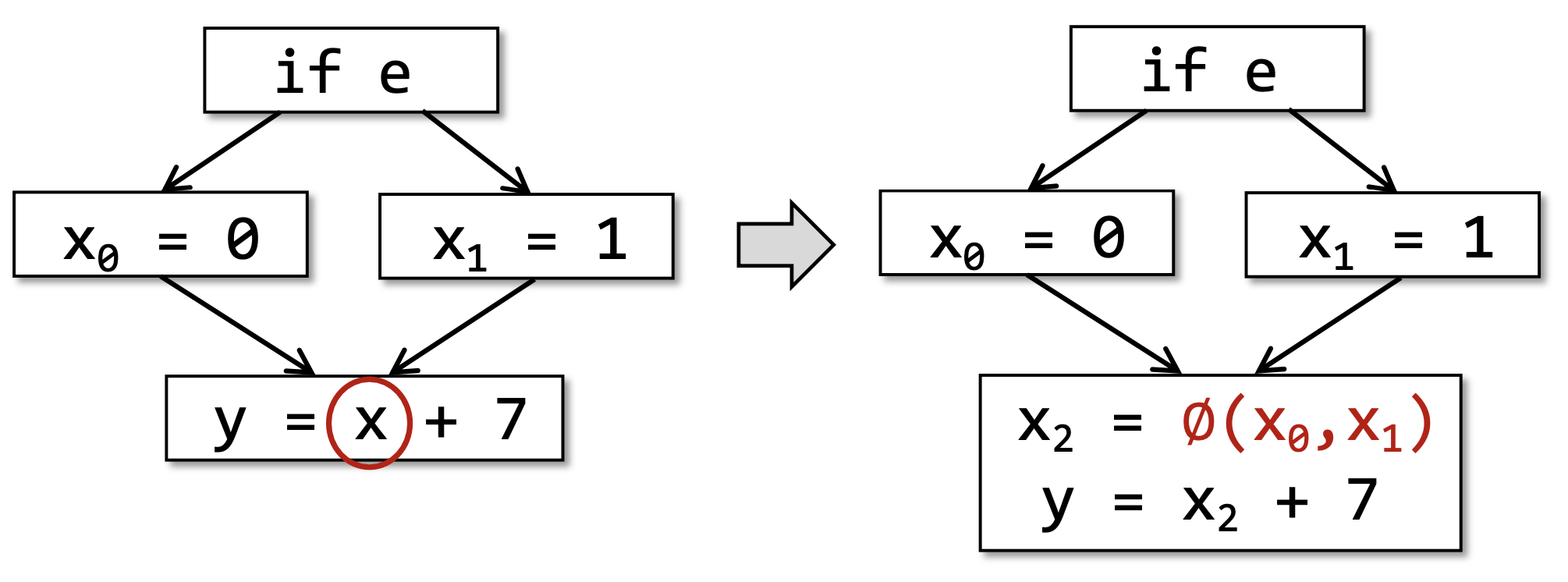
表示根据实际的路径选择 或
3.2.2 Gated SSA (选学)
使用递归的
合并来自不同路径的变量定义 与 的区别在于: 有一个额外参数 flag 表示条件(增加了控制流语义)
使用
初始化循环迭代变量, 的操作与SSA的 一致,但是 仅用于产生进入循环时迭代变量的值。 使用
获取离开循环时迭代变量的取值(即无论循环了多少次,离开循环时迭代变量的最终值)。
3.2.3 其它方案
- Hashed SSA
- SSI:Static Single Information
- IPSSA
- SSU:Static Single Use
3.3 构建SSA的复杂度
尽管SSA形式的代码相较于非SSA形式引入了额外的变量,看似十分繁琐,然而
- 非SSA IR转换为SSA IR的时间复杂度几乎是线性的
- 非SSA IR转换为SSA IR的空间复杂度几乎是线性的
- 构建的SSA IR体积通常不超过非SSA IR的常数倍
4. 基本块与控制流图
4.1 基本块(Basic Block)
基本块是指一段顺序执行的最大的连续代码序列,满足以下条件:
- 只能从第一条指令进入基本块
- 只能从最后一条指令离开基本块
4.2 控制流图(Control Flow Graph)
控制流图(Control Flow Graph,CFG)是描述程序基本块之间控制流关系的有向图。
- 节点:基本块
- 边:基本块之间的跳转关系
- 如果存在一条从基本块A到B的边,称A为B的前驱(predecessor),B为A的后继(successor)。
4.3 控制流图的作用
- 支撑数据流分析:如活跃变量分析、常量传播等。
- 构建 SSA:插入
指令需要依赖 CFG 的支配关系。
4.4 控制流分析
从3AC构建控制流图的过程称为控制流分析(Control Flow Analysis, CFA)。
定义:每个Basic Block的第一条指令称为一个 leader
控制流分析具体算法如下:
- 识别所有的 leader:
- 程序的第一条指令是一个 leader
- 所有跳转指令的目标是 leader
- 所有跳转指令的下一条指令是 leader
- 按照 leader 划分3AC,形成基本块
- 构建边:
- 如果存在从基本块A到B的条件 / 无条件跳转,则增加一条从A到B的边。(跳转边)
- 如果基本块A的最后一条指令是一个条件跳转,并且基本块B在原始三地址码中紧跟在A的后面,则增加一条从A到B的边。(顺序边)
- 识别所有的 leader:
一个例子(Entry 和 Exit 是人为定义的两个节点,表示入口和出口):
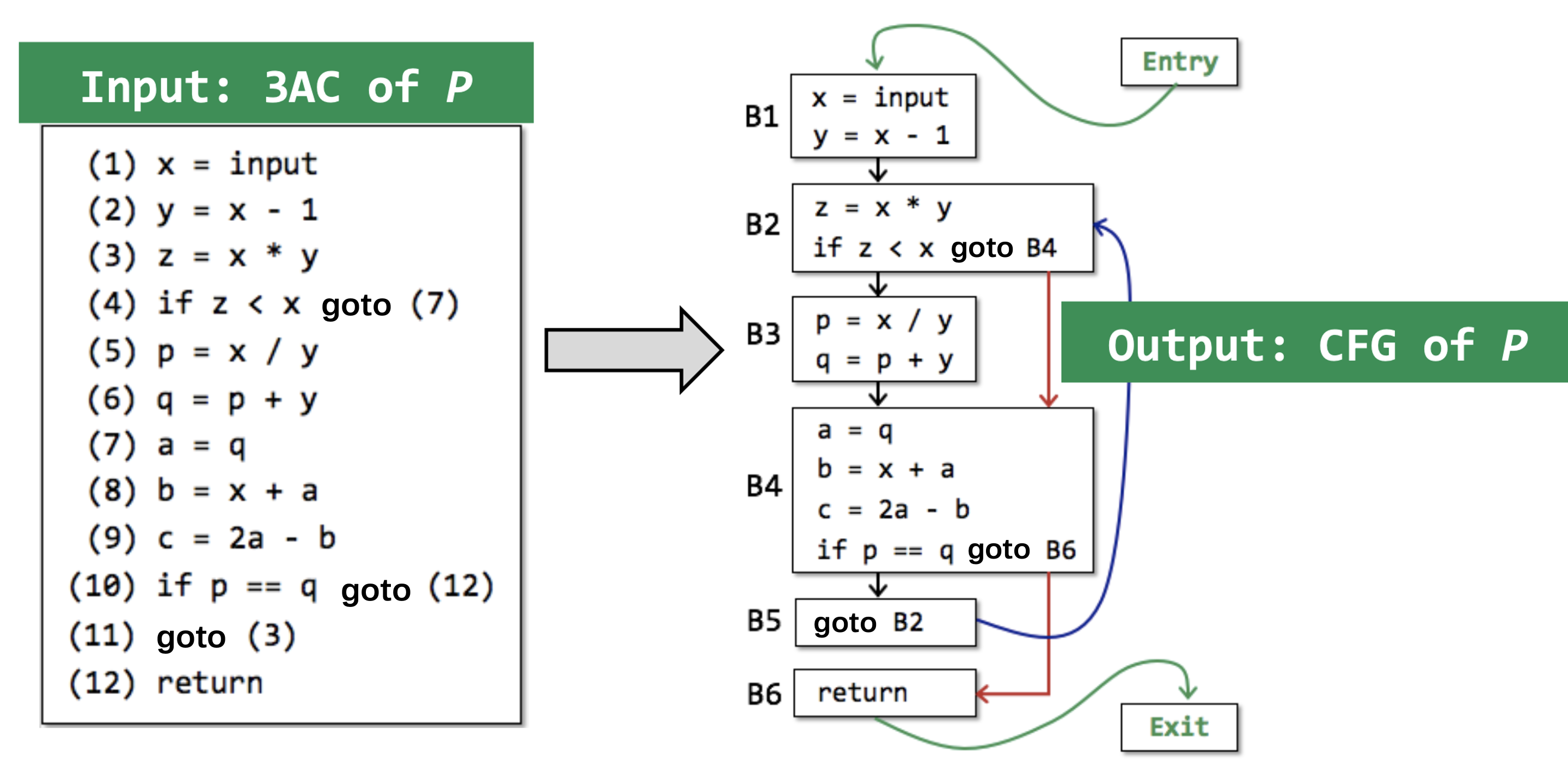
4.5 支配与控制依赖
4.5.1 支配(Dominance)与后支配(Post-Dominance)
在控制流图中,一个基本块 A 支配(dominate) 另一个基本块 B,当且仅当:
所有从Entry(入口块)到 B 的路径都必须经过 A
特别地:
Entry支配所有块
每个块也支配自己
在控制流图中,一个基本块 A 后支配(post-dom) 另一个基本块 B,当且仅当:
所有从B到Exit(出口块)的路径都必须经过A
特别地:
Exit后支配所有块
每个块也后支配自己
4.5.2 严格支配(Strict Dominance)
- 如果 A 支配 B 且 A ≠ B,则称 A 严格支配 B。
- 类似地,可以定义严格后支配。
4.5.3 直接支配(Immediate Dominator, IDOM)
- 如果 A 严格支配 B,并且不存在 C,使得 A strict-dom C,C strict-dom B,则称A 直接支配 B。
- 类似地,可以定义严格后支配。
4.5.4 支配树(Dominator Tree)
控制流图中各基本块按直接支配关系构成一棵树,称为支配树。
- 节点:Basic Block
- 边:Immediate Dom relation
构建支配树的时间复杂度几乎是线性的。
示例:
(Nearest) Common Dominator (最近)公共支配者
- 本质上是求树节点的最近公共祖先
- 经过几乎线性时间的预处理之后,可以在常数时间内获得查询结果
- 应用:找到程序中未定义即使用(use-before-def)的变量
- 找到一个变量的所有定义(def)
- 计算所有def的Nearest Common Dominator,如果Nearest Common Dominator不支配某个use,则说明可能是一个use-before-def
- 本质上是求树节点的最近公共祖先
4.5.5 支配与控制依赖(Control Dependence)
- 控制依赖 Control Dependence 的定义:
- 基本块B控制依赖于基本块A当且仅当A的执行结果决定B是否会执行
- 控制依赖的等价定义,version1:
- A有多个后继
- 有的后继能到达B,但不是所有的后继都能到达B
- 控制依赖的等价定义,version2:
- B后支配A的一个后继
- B不后支配A的所有后继
4.5.6 控制依赖图(Control Dependence Graph)
控制流图中各基本块按控制依赖关系构成的图,称为控制依赖图
- 节点:Basic Block
- 边:Control Dependence relation
由控制依赖的等价定义version 2,给定CFG和后支配树,可以线性时间地构造控制依赖图
至此,我们得到了中间代码的三种重要的数据结构:数据流图(Control Flow Graph) 、支配树(Dom Tree)/ 后支配树(Post-Dom Tree)、控制依赖图(Control Dependence Graph)
示例(三种重要数据结构):
4.5.7 支配前沿(Dominator Frontier)
一个基本块B的支配前沿
为满足以下条件的基本块集合 - 是B以及被B支配的基本块的直接后继
- 不被B严格支配
示例:
基本块集合的支配前沿:
迭代的支配前沿(Iterated Dominance Frontier,IDF):
, - 不断迭代直到不动点(fixed point),即
IDF与
指令构建: 找到变量 x 定义的所有基本块,组成集合
计算
,即为所有 指令应该插入的位置 指令具体合并哪些变量,通过查询Dominator Tree和CFG确定 示例:
x 分别定义在 A、B、C 三个基本块中, 且
。
4.6 自然循环(Natural Loop)
4.6.1 流图中循环相关概念
源代码中的一个循环语句通常对应了CFG中的一个循环(Loop)。CFG中的一个Loop指从一个基本块Header出发,经过若干条边后回到Header的一条路径。
对于CFG中的一个Loop,有以下的概念:
- Header:进入循环时经过的第一个节点,是Loop的一部分
- Pre-Header:如果Header只有一个不属于Loop的前驱,则称Header的前驱为Pre-Header
- Latch:属于Loop并且有一条指向Header的边的节点
- Latch直译为“门闩”,表示一旦撞到它就有可能走回头路,回到Header,从而被“闩”在Loop里出不去
- Exit:属于Loop并且有一条指向Loop以外节点的边
- 表示有可能从该节点离开循环
- Back edge(回边):即由 Latch 指向 Header 的边
- Exiting edge(退出边):即由 Exit 指向 Loop以外节点的边
一张图直观理解以上概念:
4.6.2 自然循环
- 如果一个Loop满足以下要求,则称为 Natural
Loop(自然循环)
- 只有一个 Header 作为循环入口
- Loop 中所有节点都被 Header 支配
- 所有从Entry开始进入循环的路径都必须经过这个唯一的 Header
- 是最大强连通分量(Max SCC)
- 每个节点都可以到达Loop中其它所有节点
- 只有一个 Header 作为循环入口
- 上图中的 Loop 即是一个 Natural Loop。
- 并不是所有的 CFG 中的 Loop 都可以用 Natural Loop 表示,一些 CFG 具有不可归约的 Loop。
- 大多数高级语言(如Java、Rust等)编写的代码都天然满足循环体只有一个入口的要求,从而其 CFG 中的 Loop 都可以归约为 Natural Loop。
4.7 过程间控制流
- 以上所讨论的 CFG 通常用于描述单个函数内(Intraprocedure)的控制流。
- 然而,在真实的程序设计中,不太可能把所有代码都写在一个函数内,也不太可能不使用任何外部库函数(如
stdio.h)。 - 这就带来了对不同函数间(Interprocedure)控制流分析的要求。
4.7.1 调用图(Call Graph)
调用图描述程序中各过程(Procedure)之间的调用关系
- 节点:程序中的 函数(Function)或 方法(Method)
- 边:如果过程A中调用了过程B,则产生一条从A到B的边
例子:
程序
1
2
3
4
5
6
7
8
9
10void foo() {
bar();
baz(123);
}
void bar() {
baz(666);
}
void baz(int x) {}
调用图
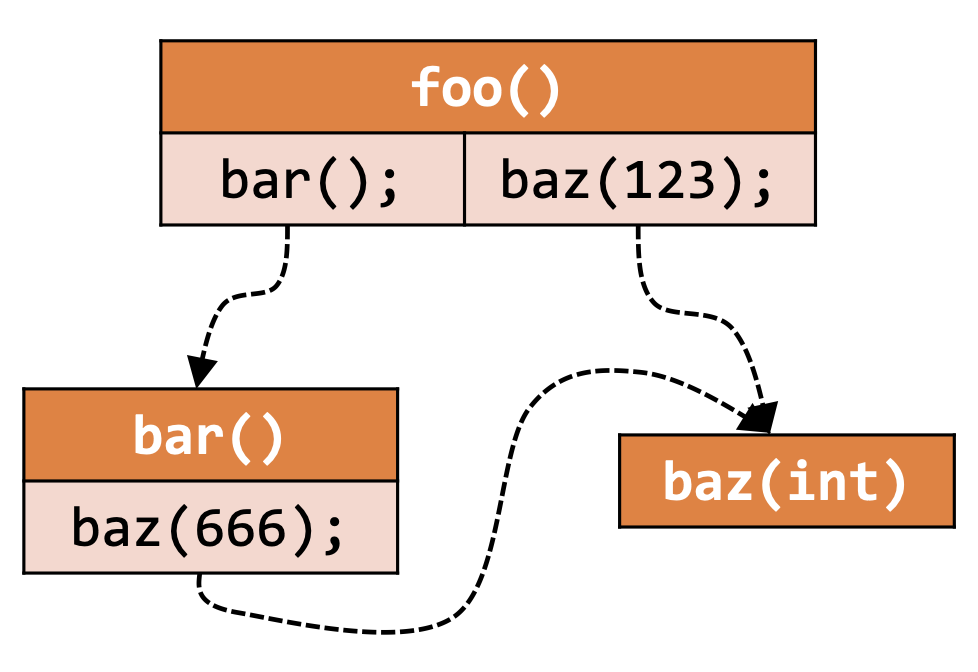
4.7.2 过程间控制流图(Interprocedural Control Flow Graph)
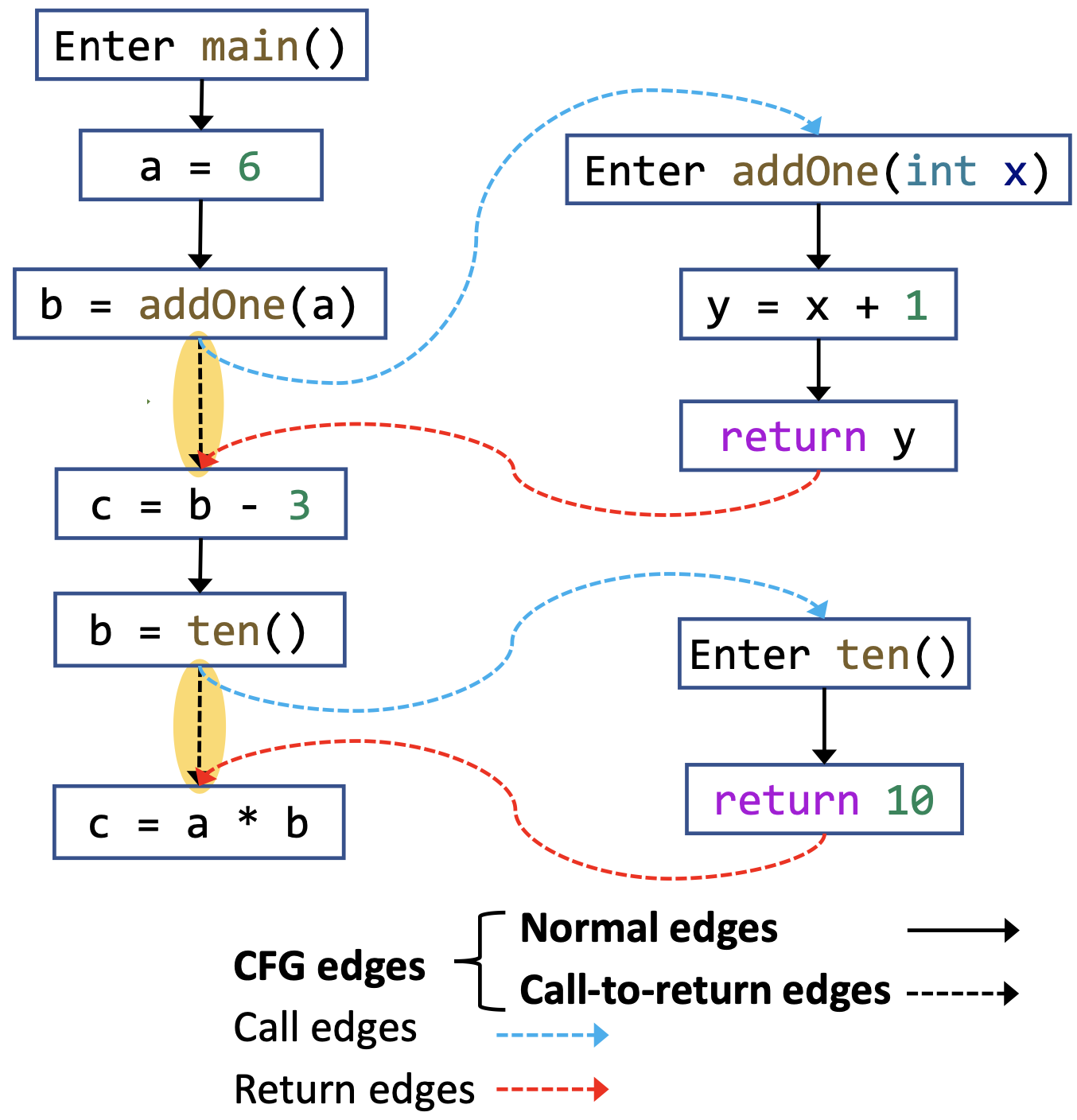
CFG 描述了单个函数内的控制流,而 ICFG(Interprocedural Control Flow Graph,过程间控制流图)则可以描述一般的多函数程序的控制流结构。
ICFG定义:
- 在CFG的基础上,增加两种额外的边
- 调用边(Call Edge):从调用者(Caller)的调用点到对应的被调用者的 Entry 的边;
- 返回边(Return Edge):从被调用者的 Exit 到 返回点(Return Site,调用点的下一条语句) 的边。
- 通常,我们保留一条直接连接调用点到返回点的边,这与后续将要学到的数据流分析(Data Flow Analysis,DFA)有关。
- 在CFG的基础上,增加两种额外的边
例子:
程序
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int addOne() {
int y = x + 1;
return y;
}
int ten() {
return 10;
}
void main() {
int a, b, c;
a = 6;
b = addOne(a);
c = b - 3;
b = ten();
c = a * b;
}ICFG
4.7.3 虚方法调用问题
- 我们在Java课程中学到过,在调用声明为
A类型的对象a的实例方法f()时,实际调用的是a的运行时类型所决定的方法版本,而未必是静态类型A中定义的方法f- 即,
a.f()实际上可能调用的是A的某个子类的方法f - 这样的方法
f也称虚方法(Virtual Method)
- 即,
- 由于在编译期我们不能动态运行源代码,所以无法精确确定
a的真实类型。因此,这一语言机制为 ICFG 构建带来了困难。 - 为了应对虚方法调用问题,精确地构建ICFG,不同的技术被提出:
- Class Hierarchy Analysis(类层次分析,CHA)
- Pointer Analysis(指针分析)
- 具体内容将在后续章节中介绍。